L’explosion des volumes de données se traduit par une évolution des interfaces et des protocoles d’accès aux données.
Dans Divers
L’explosion des volumes de données se traduit par une évolution des interfaces et des protocoles d’accès aux données.
Au cours des dernières années, les protocoles NAS comme CIFS et NFS ont progressivement pris le dessus sur les protocoles d’accès en mode bloc comme FC ou iSCSI, une montée en puissance qui s’est effectuée en parallèle de l’explosion des volumes de données non structurées. Depuis quelques années, ce sont les technologies de stockage objet qui prennent progressivement le relais des technologies de stockage NAS dans les très grands environnements de stockage non structuré.
Il existe aujourd’hui de multiples systèmes de stockage objet comme Atmos d’EMC, Amazon S3, d’AWS, Windows Azure Storage, OpenStack Swift… Ces nouveaux systèmes s’appuient sur des protocoles de communication de type RESTful, des protocoles simples d’emploi et souples, que l’on peut intégrer simplement à des applications existantes (backup, archivage analytique…).
Comme les fichiers, les « objets » contiennent des données mais contrairement aux systèmes NAS, les systèmes objets n’organisent pas les objets dans des hiérarchies structurées (typiquement des arborescences de répertoires). Les objets sont en général organisés dans un espace d’adressage plat et éventuellement dans des conteneurs de plus haut niveau parfois appelés « buckets » (littéralement des seaux).
Une des caractéristiques intéressantes des systèmes objets est qu’ils associent un ensemble de métadonnées très riches aux objets qu’ils stockent. Selon les systèmes, les objets peuvent être retrouvés par une recherche sur ces métadonnées, par leur identifiant unique ou par un système de key/value store. A aucun moment l’utilisateur n’a à se poser la question de savoir sur quel serveur ou nœud l’objet est stocké (contrairement par exemple à un système NAS, où il faut connaître le serveur où se trouve le fichier puis naviguer dans l’arborescence jusqu’à son emplacement).
D’une certaine façon on peut comparer le stockage objet à un système de consigne. Lorsqu’un client dépose un objet, il reçoit un ticket, mais ne se préoccupe pas de l’endroit où sera stocké son objet. Sa seule préoccupation est qu’en échange du ticket il pourra retrouver son objet. Et dans certains cas, s’il a déposé plusieurs objets dans un panier, il pourra revenir retirer le panier entier ou seulement un des objets du panier.
L’accès aux systèmes de stockage objet se fait en général au travers d’API de type RESTful qui s’appuient sur des commandes HTTP pour s’interfacer avec le stockage sous jacent. Les commandes basiques dont des commandes de type GET, PUT et DELETE pour lire, écrire et effacer des objets. Les API les plus couramment utilisées sont les API Atmos d’EMC, les API S3 d’Amazon et l’API Swift d’Openstack. Il est à noter que l’utilisation de commandes HTTP rend les systèmes de stockage objets bien adaptés à un usage cloud car ces commandes traversent bien les pare-feux et se prêtent aussi bien aux mécanismes de sécurisation réseau du web (et notamment l’usage de SSL)
Le stockage lui-même s’effectue sur un ensemble de nœuds distribués qui assurent le stockage et la protection des données, généralement par des mécanismes d’erasure coding, de duplication (chaque objet est écrit plusieurs fois sur des nœuds différents, ce qui permet d’assurer que les objets seront accessibles même en cas de défaillance d’un nœud) ou de réplication géographique (ce qui permet d’accéder aux données avec des performances acceptables depuis plusieurs sites géographiquement distribués). La nature distribuée de ces systèmes permet ainsi d’assurer une grande résilience. Chaque système offre des caractéristiques différentes en matière de protection de distribution et de performances. Certains sont bien adaptés au stockage de grands volumes de petits objets tandis que d’autres sont bien adaptées au stockage d’objets très volumineux (images, vidéos…).
Typiquement ces systèmes offrent un coût très compétitif au gigaoctet et sont bien adaptés aux applications de stockage de masse de données à faible valeur, à l’archivage de données et au stockage en cloud. Il est à noter que récemment la plupart des fournisseurs de systèmes objets ont aussi greffé des interfaces d’accès plus traditionnelles à leurs systèmes. De plus en plus il est ainsi possible de déverser des données dans ces systèmes en utilisant des protocoles NAS comme NFS ou CIFS, ce qui permet typiquement à des applications ne supportant pas (encore) les protocoles objets d’accéder à ses systèmes.
Des équipes universitaires et les centres de R&D travaillent sur le stockage objet depuis une dizaine d'années au moins. L'université de Carnegie Mellon a fourni un gros effort de théorisation autour du NASD (Network Attached Storage Device), antécédent direct de plusieurs implémentations actuelles d'architectures de stockage objet.
Les architectures de stockage objet constituent davantage une famille de technologies adoptées par de nombreux fournisseurs qu'un modèle unique et standardisé.
Leur point commun est de toujours s'affranchir des modèles actuels du stockage en substituant aux blocs et aux fichiers une nouvelle unité de base : l'objet.
Ces architectures ont aujourd'hui deux utilisations principales :
Le stockage de données repose sur deux principes fondamentaux :
Les blocs correspondent au fonctionnement physique des médias de stockage, les disques en particulier. Chaque bloc est identifié par un système de coordonnées : cylindre, plateau, piste, secteur.
Les fichiers correspondent à ce qui est manipulé par les programmes, et sont identifiés par un nom et un chemin : /nom_de_machine/disque/dossier/nom_de_fichier.
Les systèmes d'exploitation gèrent les blocs et maintiennent la correspondance entre les blocs et les fichiers (mapping), au moyen de tables d'allocations et d'inodes (blocs d'identification des fichiers Unix). Ils traitent aussi les opérations de maintenance additionnelles : cohérence, allocation d'espace, journalisation, optimisation, défragmentation.
L'architecture objet distribue le traitement du stockage
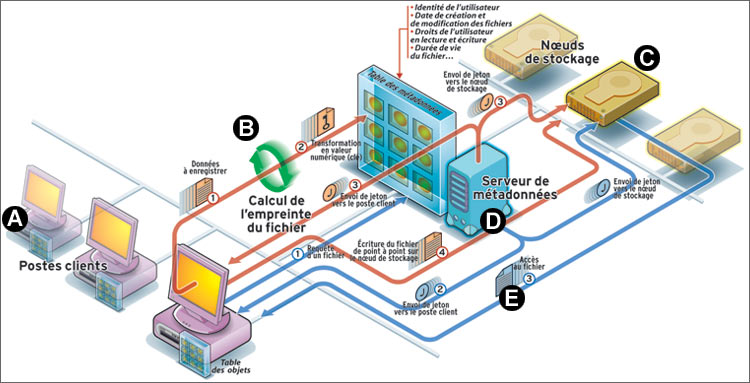
A - Les clients n'ont plus à traiter eux-mêmes leur stockage en maintenant un système de fichiers avec des chemins de localisation physique. Ils se contentent de maintenir une table d'objets.
B - Lors d'une opération d'écriture, le client calcule une empreinte de son fichier et l'envoie au serveur de métadonnées. Celui-ci détermine sur quel nœud de stockage il sera inscrit, l'index, et envoie un jeton au client et au nœud de stockage. C'est avec ce jeton qu'ils communiqueront pour l'opération d'écriture proprement dite.
C - Les nœuds de stockage sont des disques intelligents, ils stockent les données, contrôlent leur intégrité, les sécurisent et communiquent directement avec les clients pour les opérations de lecture-écriture.
D - Le serveur de métadonnées, qui est soit un serveur indépendant (en cluster pour plus de sécurité), soit réparti sur les nœuds de stockage, détermine la localisation des objets sur les nœuds de stockage lors de l'écriture comme de la lecture.
E - Lors d'une opération de lecture, le client demande au serveur de métadonnées la localisation de son fichier, ce serveur envoie un jeton vers le nœud de stockage et vers le client, l'opération de lecture s'effectue ensuite directement entre eux.
Sources de ce document sur ces trois liens : lien1 - lien2 - lien3