Avant d’entrer dans le vif du sujet, je voudrais faire un petit rappel sur les futurs enjeux de l’univers numérique qui forcement, remettent en cause les solutions traditionnelles de stockage.
Dans Infrastructures (hyper) convergentes
Avant d’entrer dans le vif du sujet, je voudrais faire un petit rappel sur les futurs enjeux de l’univers numérique qui forcement, remettent en cause les solutions traditionnelles de stockage.
90 % du volume actuel de données ont été créés au cours des deux dernières années. L’univers numérique est en pleine expansion. Les ordinateurs et autres téléphones mobiles seront bientôt dépassés par les équipements informatiques portables et les objets connectés. Les objets connectés mobiles (puces RFID, smart cars, jouets, et même colliers de chien…), représentent aujourd’hui 18% de l’environnement digital mondial. Leur part devrait atteindre 27 % dans six ans, selon une étude publiée par IDC pour le compte d’EMC. D’après cette même étude, en 2020, le volume de données généré dans le monde par les objets connectés sera de 44 zettabytes, soit plus de 40 000 milliards de Gb (un Zo égal 1021 octets). En 2013, le volume de données était de 4,4 zettabytes, la progression sera donc de x10 en 7 ans. Dans six ans, 212 milliards de ces appareils seront en activité sur la planète. On dénombre à ce jour 20 milliards de dispositifs ou d’objets permettant de se connecter à internet, voire entre eux. Une plateforme comme Twitter génère à elle seule 7 téraoctets de données par jour.
D’ici là, il est nécessaire d’anticiper et de prévoir de nouveaux modes de stockage, d’accès et de protection de cette gigantesque masse d’informations. En effet, le stockage traditionnel, qui s’appuie sur l’ajout de disques pour stocker les nouvelles données, ne tient plus car le coût en est devenu prohibitif et les performances des disques ne permettent plus de soutenir la demande des utilisateurs sur ces données. Pour répondre au défi de la performance, la transition de disques magnétiques vers des solutions flash est une autre tendance qui anime le marché. Plusieurs constructeurs proposent des baies 100 % flash pour le stockage primaire des données afin de suivre la cadence. Mais là encore, on ne fait que déplacer le goulet d’étranglement actuel des I/O vers les contrôleurs eux-mêmes, d’où la nécessité, là encore, de rechercher de nouvelles architectures pour répondre au problème.
Le marché du stockage sur disque devrait continuer à croître, mais il devra rapidement évoluer vers des solutions qui permettent d’augmenter les ressources plus facilement et pour des coûts moindres comme des produits de stockage « Scale out » qui permettent de faire face au volume par simple ajout de nœuds de contrôleurs, qu’ils soient virtuels ou matériels, en s’appuyant sur des technologies hyper-convergées. Actuellement, c’est le seul moyen pour accompagner la croissance de la capacité brute de stockage nécessaire qui, selon le Gartner Group, devrait être de l’ordre de 50 % d’ici à 2016. Des entreprises, comme Pure Storage, Scality, Simplivity, Nirvanix, Nutanix et bien d’autres encore ont désormais leur mot à dire. La plupart d’entre elles ont choisi nativement des architectures « Scale out » couplée à la technologie Flash pour répondre aux problèmes de stockage posés par les environnements Cloud et les environnements fortement virtualisés. Ils investissent tous sur de nouvelles technologies de stockage en proposant des concepts innovants comme la convergence ou l’hyper-convergence, le stockage objet (présenter un fichier à travers HTTP par des API, le plus souvent REST), le stockage exclusivement sur des baies utilisant la technologie Flash.
Reste que la virtualisation du stockage par couche logicielle (système de fichiers distribué) qui sépare le matériel sous-jacent de l’intelligence de stockage (réplication, déduplication, tiering des données, etc…) est le concept le plus avancé et le plus pertinent aujourd’hui pour répondre aux besoins de grosses volumétries et de performances, avec sa technologie « Scale out » hyper bien adaptée.
Nutanix, avec son système de fichier distribué NDFS en est la meilleure preuve car elle rencontre un beau succès auprès de nombreux grands comptes français.
Ceci étant dit, revenons à nos moutons. On parle de plus en plus des nouvelles technologies et solutions de stockage, mais qu’en est-il vraiment ? Quels sont les éléments à prendre en compte ? Nous allons nous intéresser à la résilience qui est un des facteurs clé des nouvelles technologies de stockage.
Un des principaux intérêts du stockage est de pouvoir mettre en place une protection automatique des données. Comme plusieurs disques physiques sont utilisés, le système doit être en mesure de dupliquer les données de l'un vers l'autre afin de pouvoir les récupérer en cas de panne de l'un des disques. Permettre à un système de survivre à une panne matérielle, c'est ce qu'on appelle la « résilience ». Le terme « résilience » désigne donc la capacité d’un système, quel qu’il soit, à continuer de fonctionner en cas de panne. Dans les infrastructures traditionnelles ou « Scale out », le système doit protéger l’intégrité des données dans les pools et les espaces de stockage, qui doivent pouvoir « survives » en cas de panne d’un disque (ou plusieurs) ou d’un nœud du cluster.
La question que l’on peut se poser, c’est de savoir si la résilience est aussi bien, voire mieux gérée avec une infrastructure hyper-convergée, implémentée d’un système de fichiers distribué versus un stockage centralisé classique (RAID) ou objet.
Nous allons donc traiter ce point dans deux parties distinctes :
Commençons par le stockage traditionnel partagé, et le niveau de RAID 5 (un des plus utilisé). La figure ci-dessous représente 3 disques SATA de 4 Tb dans une configuration RAID 5 avec un disque de secours (Hot Spare).

Prenons un exemple de scénario où l’on perd un disque. Le disque de Hot Spare est activé et la reconstruction des données commence, comme l’indique la figure ci-dessous.

Tout va pour le meilleur du monde me direz-vous, un disque est tombé en panne, le disque de Hot Spare a automatiquement pris sa place et la grappe RAID a commencé à reconstruire les données. Mais le problème dans cet exemple, aussi simplifié soit-il, c’est que les deux disques (soit une bande passante totale de 200 IOPS) doivent se reconstruire à partir d’un seul disque et la vitesse maximale à laquelle le RAID 5 va pouvoir restaurer la résilience est limitée à celle du disque de Hot Spare, soit 100 IOPS. Je vous laisse imaginer ce que ça donnerait avec un RAID 5 composé de 8 disques. Il y aurait 7 disques (soit 700 IOPS) qui reconstruiraient le nouveau disque avec seulement 100 IOPS en bande passante.
Avec cette architecture, les problèmes sont les suivants :
Maintenant que nous avons abordé ce concept, nous savons qu’une reconstruction de RAID peut prendre des heures, voir des jours, occasionnant des baisses de performances sur l’ensemble du stockage. Mais avec les nouvelles technologies hyper-convergées, ces contraintes ne sont plus vraiment un problème me direz-vous. Et bien c’est faux !
Tout ça va entièrement dépendre de la façon dont les données sont récupérées en cas de défaillance d'un disque ou d’un nœud. Prenons comme exemple une solution hyper-convergente qui utilise un stockage objet. La figure ci-dessous représente un exemple simplifié de stockage objet basé sur l’hyper-convergence. Quatre objets en noirs, A, B, C et D avec leur copie représentée en couleur mauve.
Remarque: Les objets dans le magasin peuvent atteindre des centaines (voir beaucoup plus) de Gb en volumétrie.
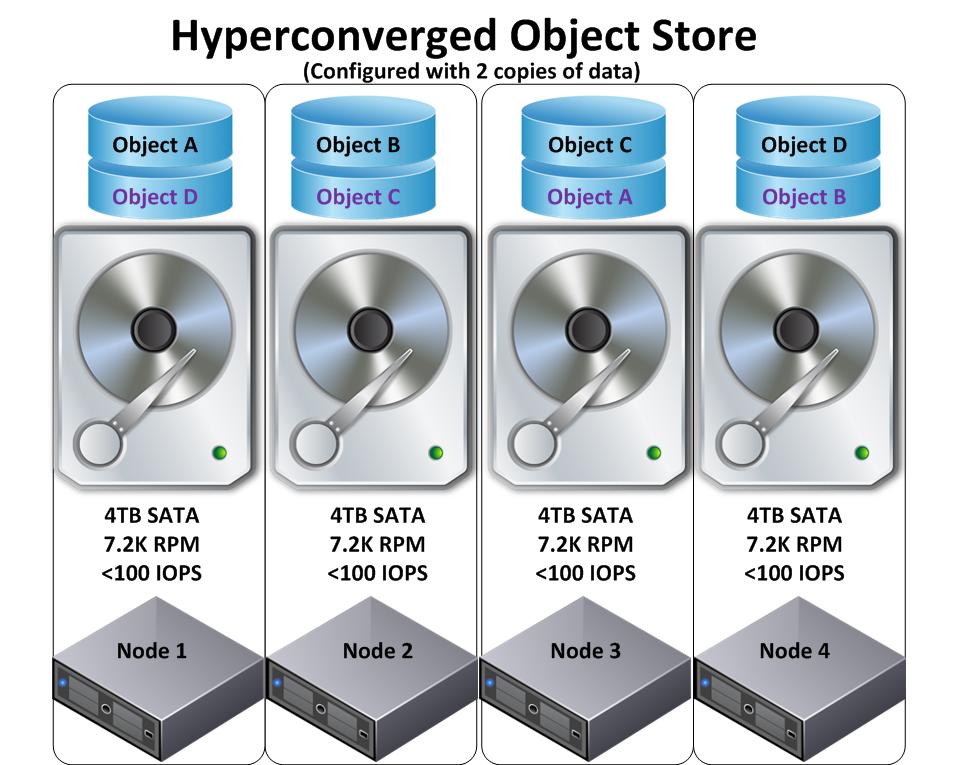
Jetons un coup d'œil sur ce qui se passerait dans un scénario où un disque viendrait à tomber en panne. Dans la figure ci-dessous, nous voyons un disque qui est en panne sur le nœud 1, ce qui signifie que l’objet A et l'objet de réplique D (mauve) ont été perdus. Le magasin d’objets devra donc se reconstruire en faisant une copie de l'objet A sur le nœud 4 et une réplique de l'objet D sur le nœud 2 pour garantir la résilience.

Cette architecture pose plusieurs problèmes :
Il convient de souligner que si des SSD sont utilisées pour le cache en écriture, l’impact est réduit et on accélère la reconstruction. Mais dans certains cas, les données sont récupérées en dehors du cache, c’est-à-dire dans le disque SAS ou SATA, et même si les écritures se font dans la SSD, on n’obtient guère d’amélioration car les écritures sont limitées par les performances en lecture dans le disque.
Les solutions de stockage RAID traditionnelles, utilisées par les SAN/NAS et les solutions hyper-convergentes plus récentes à base de stockage objet souffrent toutes les deux de problèmes similaires lors de la reconstruction automatique des données en cas de perte de disques ou de nœuds.
Pour faire suite à cette première partie, nous allons maintenant parler du concept hyper-convergent basé sur un système de fichiers distribué, basé sur GFS (Google File System) et HDFS (Hadoop Distributed File System) et dans notre cas, plus particulièrement sur celui de Nutanix NDFS (Nutanix Distributed File System).
L’objectif est de faire le comparatif entre les solutions traditionnelles SAN/NAS en RAID et l’hyper-convergence à base de stockage objet pour la protection des données.
La figure ci-dessous montre une solution hyper-convergente à 4 nœuds qui utilise un système de fichiers distribués sur 4 disques SATA identiques de 4 Tb avec une protection où la donnée est répliquée deux fois. (C’est le facteur de réplication x2 (RF2) chez Nutanix).
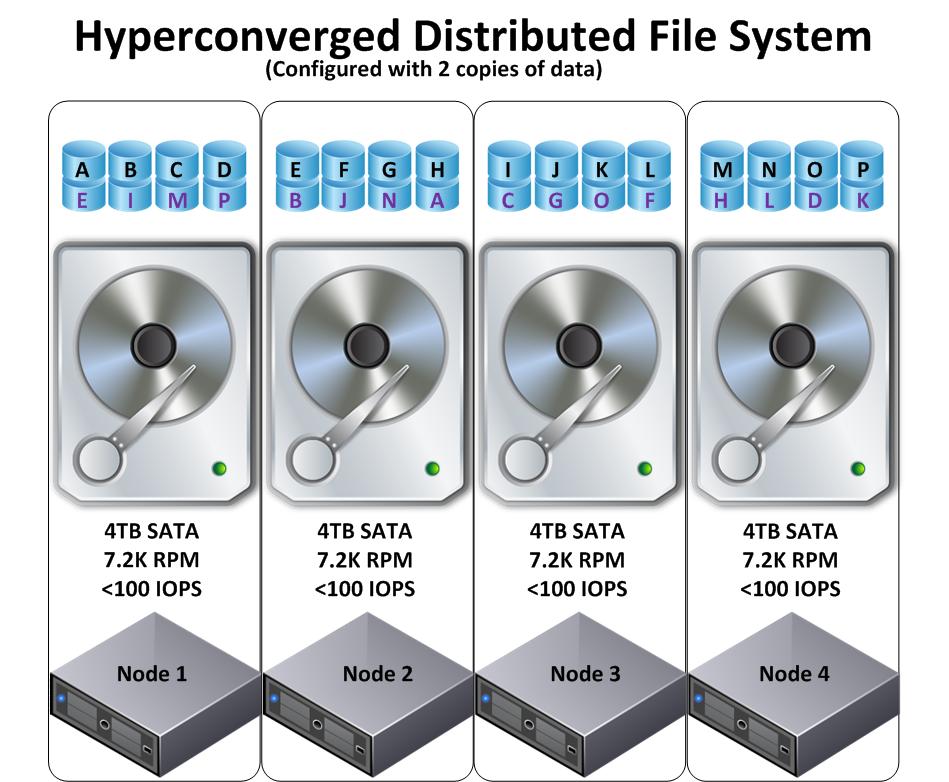
Comme on peut le remarquer, la première différence concerne les données, qui sont beaucoup plus granulaires en comparaison avec une solution hyper-convergente à base de stockage objet (vu dans la première partie).
La seconde différence, un peu moins évidente, c’est que les copies répliquées des données du nœud 1 (avec des lettres mauves), ne résident pas que sur un seul autre nœud, mais sont distribuées à travers tout le cluster. Regardons maintenant ce qui se passe quand un disque tombe en panne.
Dans la figure ci-dessous, le nœud 1 perd son disque qui héberge 8 blocs de données granulaires chacun de taille de 1 Mb.
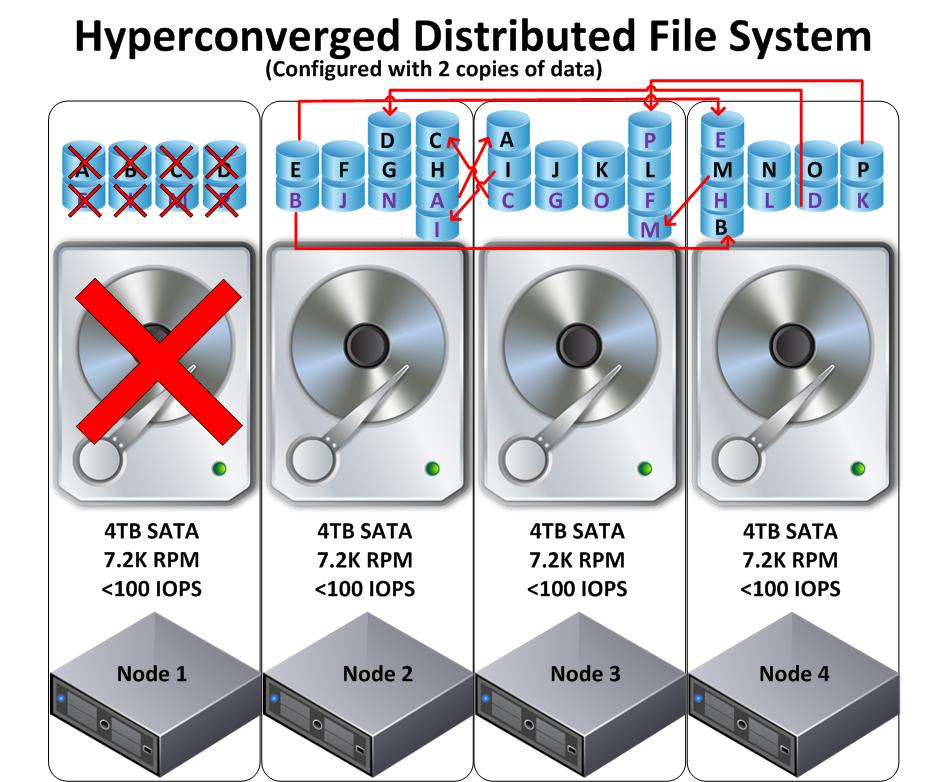
Le système de fichiers distribué détecte aussitôt que les données A, B, C, D, E, I, M, P n’ont plus qu’une seule copie dans le cluster et commence un processus de reconstruction (comme le facteur de réplication est x2, il les copie sur d’autres nœuds)
Voici les étapes de réplication :
Quel est l’impact sur chaque nœud ?
Le tableau ci-dessous est une représentation simplifiée de la charge pendant la reconstruction dans le cluster. Comme vous pouvez le constater, la charge (soit les 8 blocs granulaires de données répliquées) a été répartie entre les nœuds du cluster de façon très homogène.

Voici les avantages d'une solution hyper-convergente avec un système de fichiers distribué (utilisé par Nutanix dans notre cas).
Les solutions en RAID traditionnels sur des SAN/NAS et l’hyper-convergence utilisant un stockage objet, souffrent des problèmes similaires lors de la reconstruction automatique des données en cas de perte d’un disque ou d’un nœud.
La solution hyper-convergée Nutanix, utilisant le système de fichiers distribué NDFS (Nutanix Distributed File System), peut reconstruire la résilience, suite à une panne de disque dur ou d’un des nœuds du cluster, beaucoup plus vite et avec un minimum de conséquence sur l'impact de l’activité, grâce à son architecture modulaire et distribuée. Cela signifie de biens meilleurs performances et un rendement beaucoup plus constant pour les machines virtuelles.
Sources de ce document sur ces liens : lien1 - lien2 - lien3 - lien4